

Dify构建设备巡检工作流
部署Dify
github项目链接:
喜欢的可以点个星

好了话不多说,我们开始:
按照dify文档,选择社区版本用docker compose部署
如果还没有安装docker和docker compose,可以参考文档前提条件部署安装,值得注意的是,安装完毕后docker的根目录默认为:Docker Root Dir: /var/lib/docker,可以通过修改/etc/docker/daemon.json文件中指定"data-root":
如下:
{
"data-root": "/data"
}然后重启docker服务,在通过docker info命令查看是否生效
#重启docker
sudo systemctl restart docker
#查看docker配置信息
sudo docker info | grep "Docker Root Dir" 模型对接
dify可以通过例如deepseek、智谱ai等在线api或者本地部署的方式接入模型
平台API方式
我们用现在比较火的deepseek作为例子:
安装插件,在插件-->探索 Marketplace-->模型,根据自己的需求选择安装哪类模型插件,安装好后就可以在插件列表中看到

设置模型,点击右上角头像-->设置-->模型供应商,找到深度求索,点击设置根据帮助获取deepseek的api key填入,成功可以看到如下三个模型。
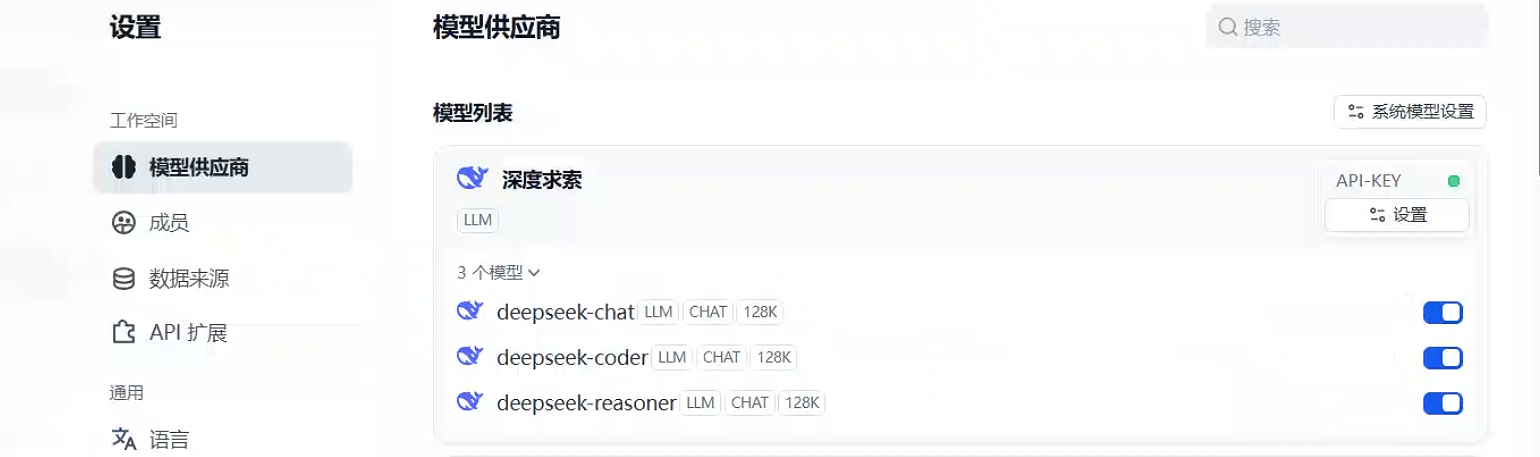
deepseek-reasoner模型对应 DeepSeek-R1具有深度思考能力,价格也更贵。如下是官网的文档https://api-docs.deepseek.com/zh-cn/quick_start/pricing
本地部署方式
博主这边是双卡4090的环境,用ollama部署了32B的模型,显存单卡占用大概是在百分40-50左右。首先进入项目地址,喜欢的也给可以给项目点个星
https://github.com/ollama/ollama 选择docker部署,点击链接进入docker hub
The official Ollama Docker image
ollama/ollamais available on Docker Hub拉取ollama镜像,运行容器,然后拉取并运行32B模型权重
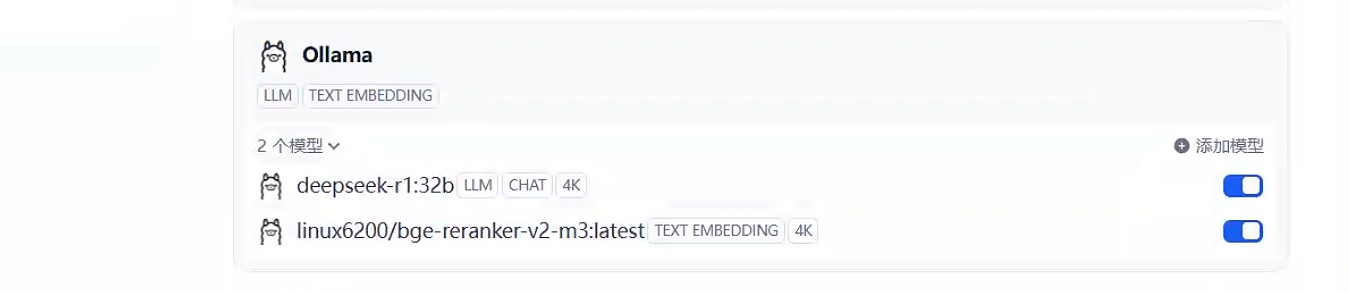
#拉取ollama镜像 docker pull ollama/ollama #运行容器 docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama #拉取并运行32B模型 docker exec ollama ollama run deepseek-r1:32bdify接入ollama,安装好ollama模型插件,点击右上角头像-->设置-->模型供应商,选择ollama,填好对应的信息后可以看到如下32B的模型
创建工作流
在创建工作流之前我们需要自己用fastapi搭建一个自定义工具,dify市场中的SSH命令执行插件测试过对于非服务器的输出会超时,大家也可以用其他方式实现这个SSH登录设备的功能。
fastapi服务端
大家可以参考下我这部分代码fastapi.rar需要把main.py中的
API_KEY = os.getenv("API_KEY", "123456")这部分秘钥改掉,或者在同目录下创建API_KEY这个文件存储秘钥然后就可以构建镜像了,把压缩包上传服务器解压,如果跟dify不在同一服务器需要把端口暴露出来
#进入fastapi目录下 cd ~/fastapi/ #构建docker镜像版本呢v1 docker build -t fastapi:v1 . #运行容器,注意要和dify的docker-worker-1容器在一个网络里 docker run -d --name fastapi --network docker_default fastapi:v1
容器运行以后我们就可以配置工具了,在工具-->自定义工具-->创建自定义工具。在schema中复制以下代码
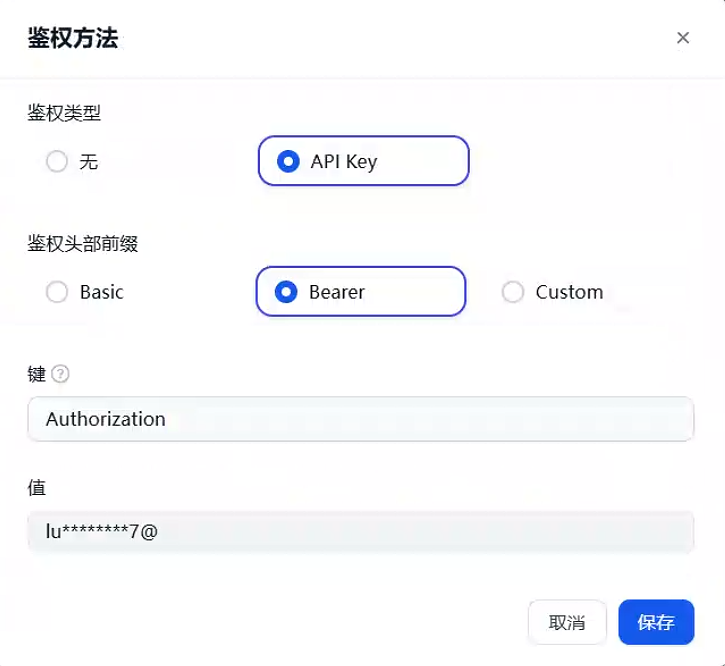
{ "openapi": "3.1.0", "info": { "title": "API Documentation", "version": "1.0.0" }, "servers": [ { "url": "http://fastapi:8000", "description": "FastAPI container in Docker network" } ], "paths": { "/execute": { "post": { "summary": "自动执行命令", "description": "这是一个通过SSH自动执行命令的工具.", "requestBody": { "required": true, "content": { "application/json": { "schema": { "type": "object", "properties": { "hostname": { "type": "string", }, "username": { "type": "string", }, "password": { "type": "string", }, "command": { "type": "array", "items": { "type": "string" }, } }, "required": ["hostname", "username", "password", "command"] } } } } } } }, "components": { } }鉴权方法选择为api key,键填入相同参数,值为之前修改的API_KEY
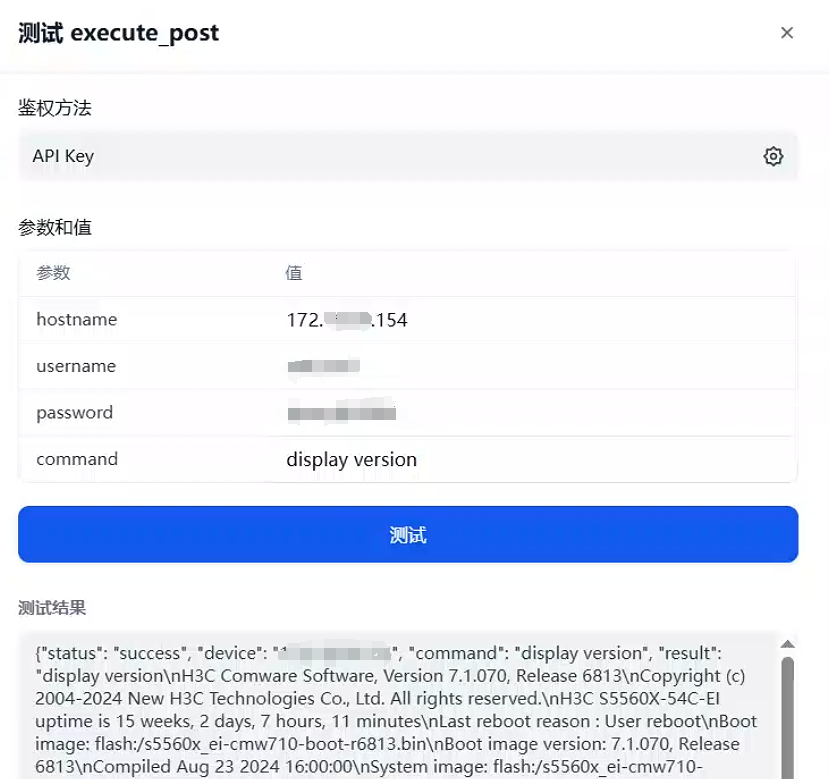
然后我们点击测试,填入参数试一下,成功执行了命令,并且将输出返回给了我们
接下来可以去创建工作流了,选择工作室-->创建空白应用-->工作流点击创建。由于本人目前需求为分析设备配置及日志,所以暂时只做了这两个功能,以下思路供大家参考
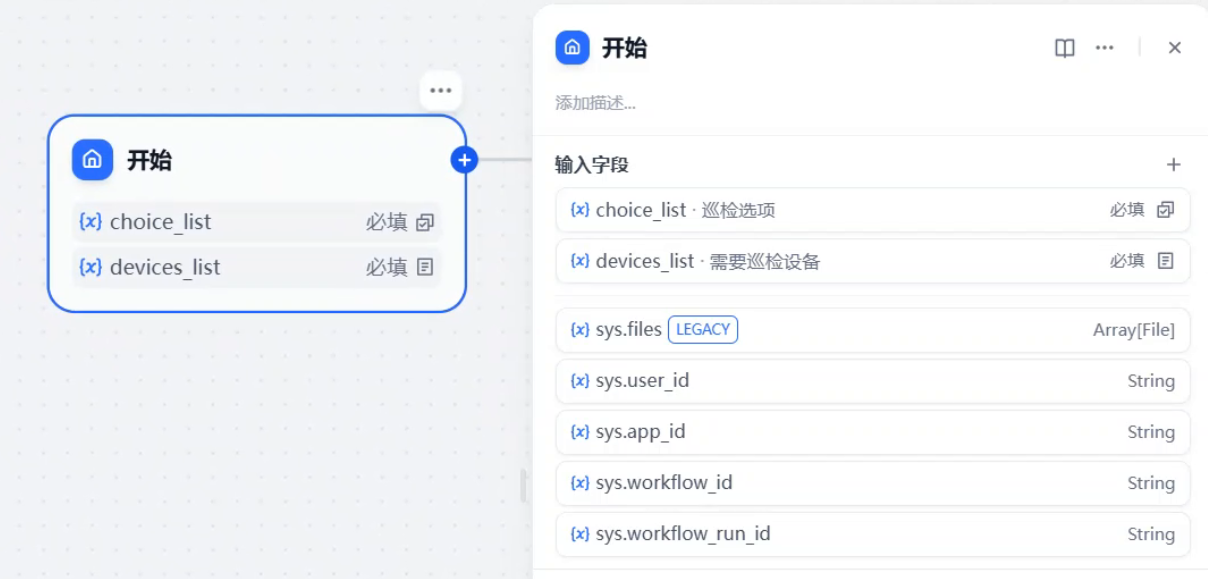
首先是开始节点,添加输入字段:
1、下拉选项:巡检日志、巡检配置
2、文件上传选项:巡检设备列表,支持批量巡检
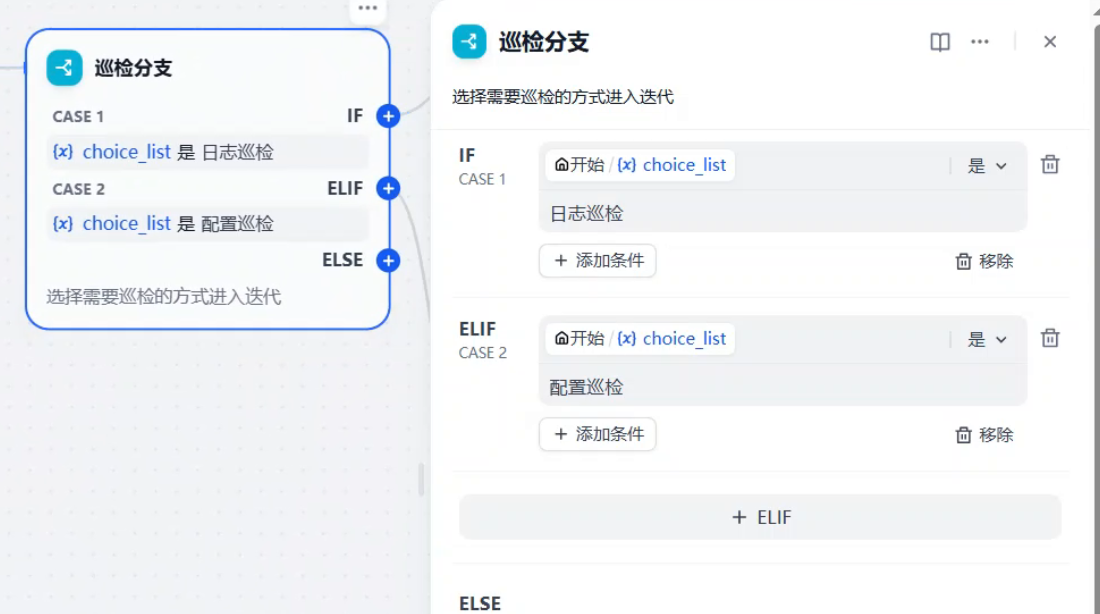
然后连接一个条件分支用于判断巡检方式进入不同的迭代循环
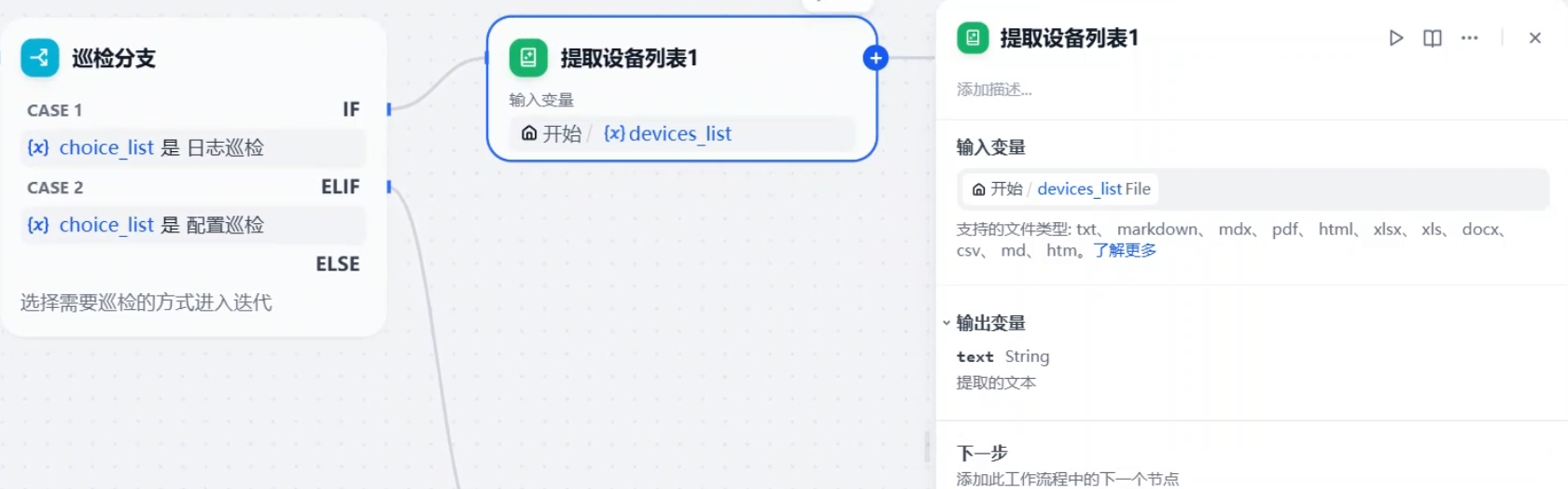
然后连接一个提取设备列表,用去将文件中的设备名称提取出来
由于迭代节点输入的类型为Array类型的数据,所以需要提前把提取设备列表节点中输出的String类型进行一个转换,我们用到代码执行这个节点,输入变量input_str也就是上一个节点的输出,输出为result是一个Arry[String]类型的数据
import re
def main(input_str: str) -> dict:
"""提取Markdown表格中非分隔线行的首列内容(含表头)"""
markdown = str(input_str)
# 解析所有表格行,并去除首尾空单元格
rows = [
[cell.strip() for cell in line.split('|')[1:-1]]
for line in markdown.split('\n')
if line.startswith('|')
]
# 识别并过滤分隔线行
valid_rows = []
for row in rows:
# 判断是否分隔线:单元格内容类似 "---", ":---", "---:"
is_separator = any(re.match(r'^:?-{3,}:?$', cell) for cell in row)
if not is_separator and row: # 非分隔线且非空行
valid_rows.append(row)
# 提取首列内容
result = [row[0] for row in valid_rows if len(row) > 0]
return {'result': result}现在就可以接上我们的迭代节点了
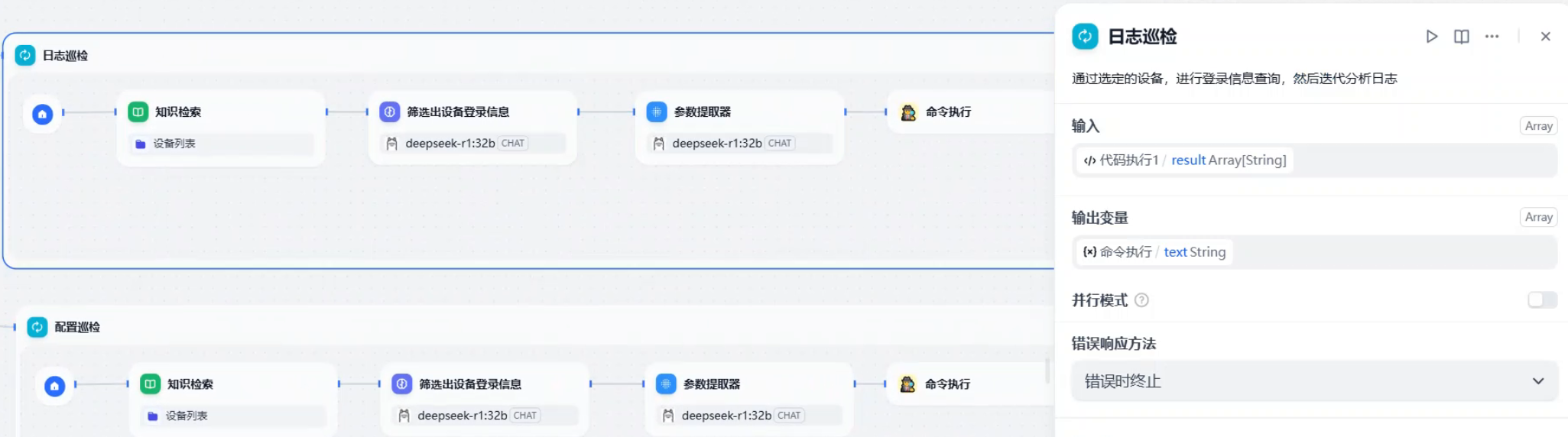
首先,迭代节点输入是上一个节点输出的result,输出为自定义工具的输出。迭代内部先调用了知识库,根据提取到的设备名称检索出对应的登录信息(ip地址、用户名、密码),知识库大致构建步骤如下:
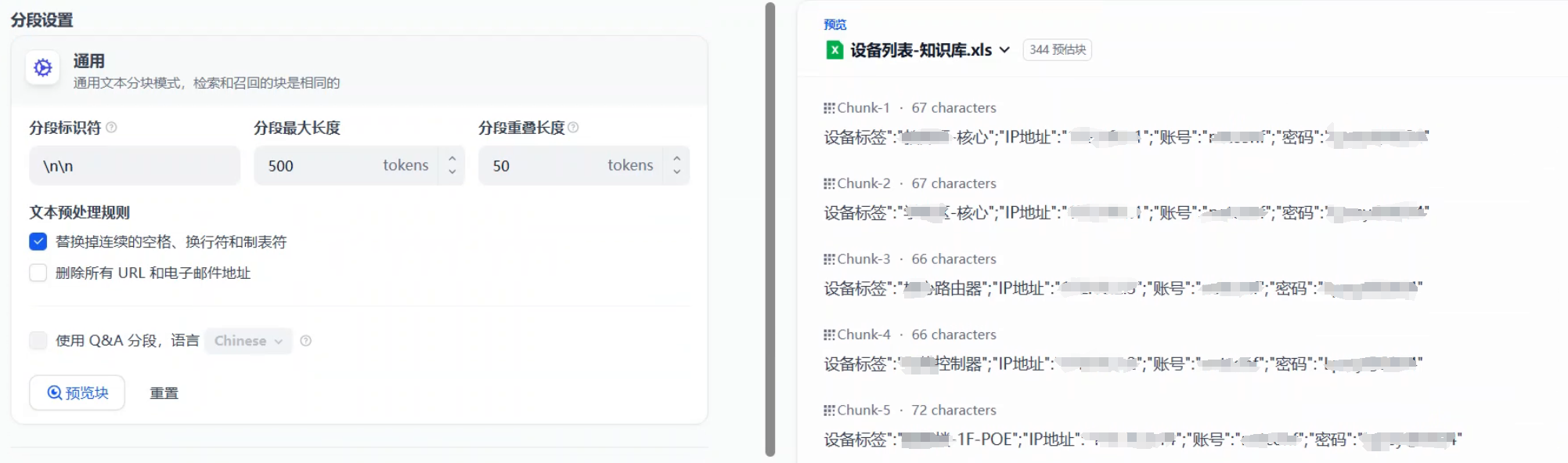
选择知识库-->导入已有文本-->选择文件上传,建议用表格把设备信息记录下来,方便系统分段。分段设置中默认就可以,然后点击预览分段,大致如下
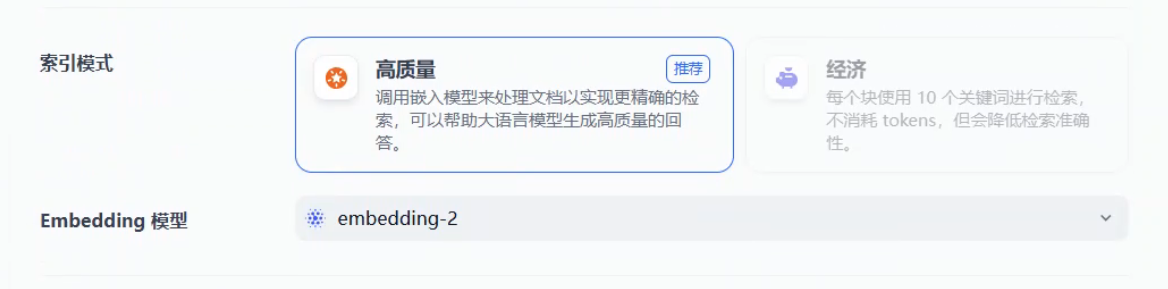
在索引方式选择高质量,选择好向量模型,这部分可以参考模型对接,在ollama上本地部署或者调用各平台的api
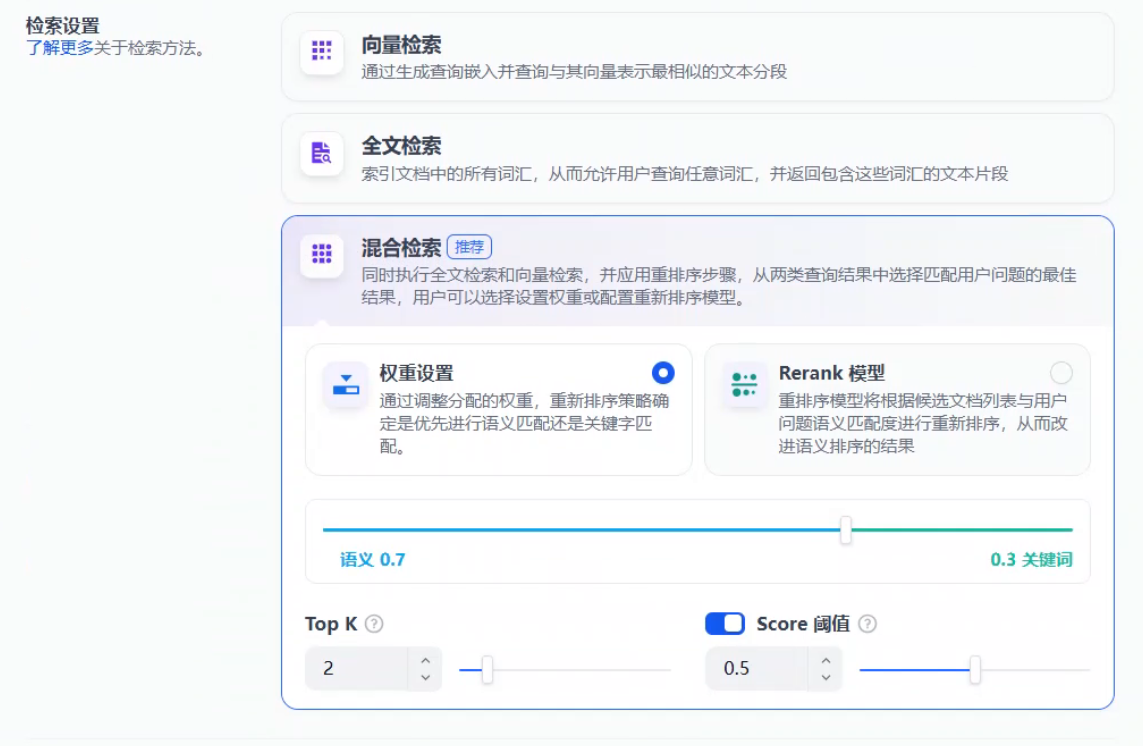
检索设置选择混合检索,可以选择权重或者用rerank模型。此处我选择了权重,设置为0.7的语义,0.3的关键词,打开score选择0.5。保存处理,等待处理结束
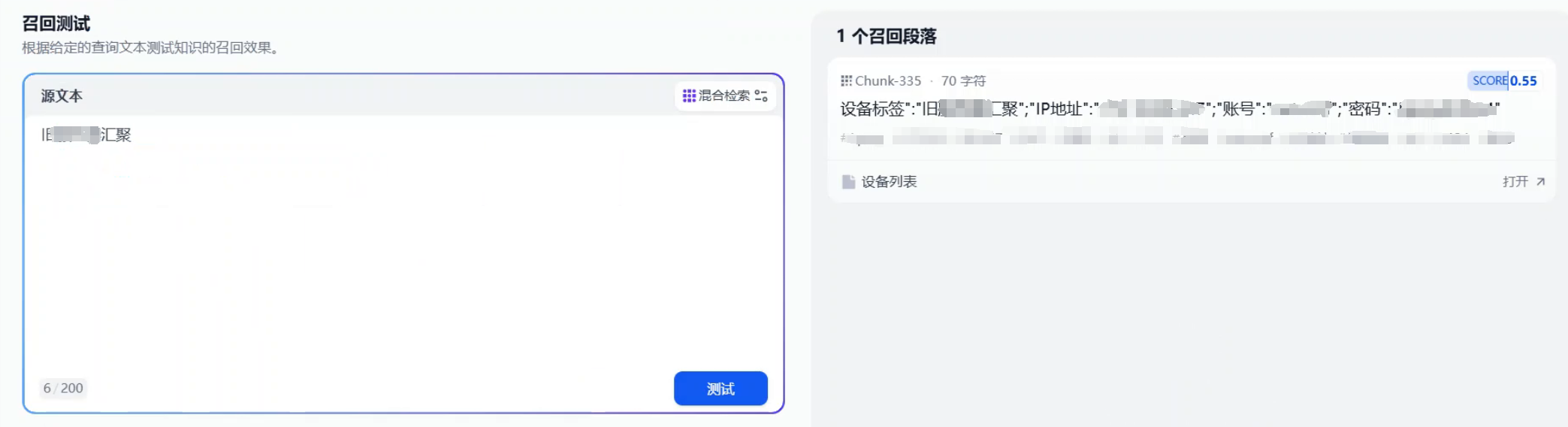
进行召回测试,确认检索效果
知识检索节点中的查询变量为迭代节点的item
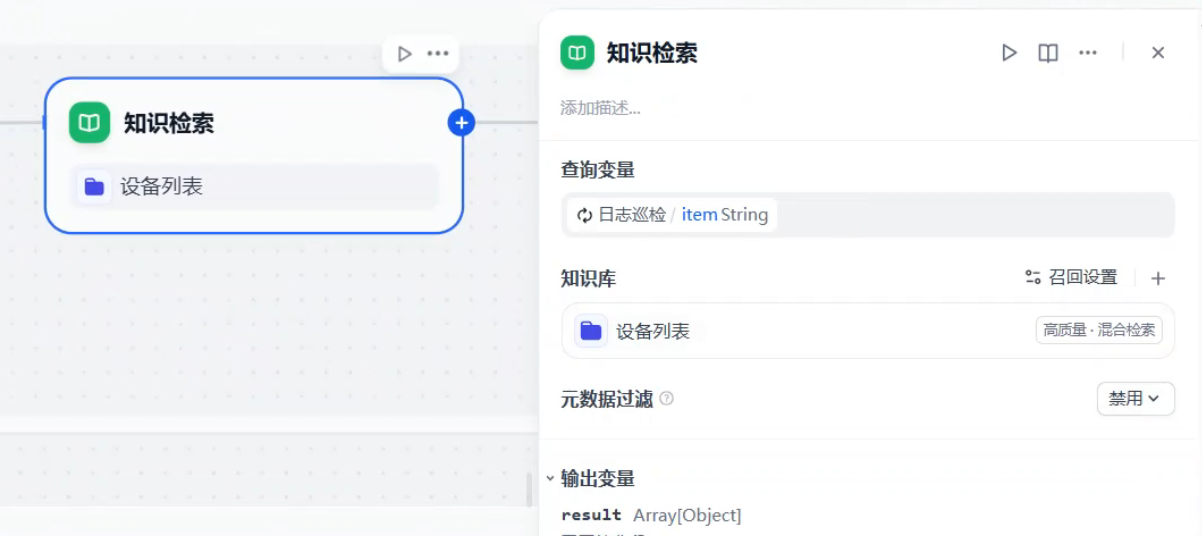
接下来我们需要一个LLM节点来帮我们从知识检索的结果中提取出设备的登录ip、用户名、密码。可以参考我以下的提示词。大家可能会问为什么不用参数提取节点用大模型直接提取参数,这部分大家可以关注下参数提取节点的接入只能为String类型数据,而知识库检索的输出的是Array[Object]的类型
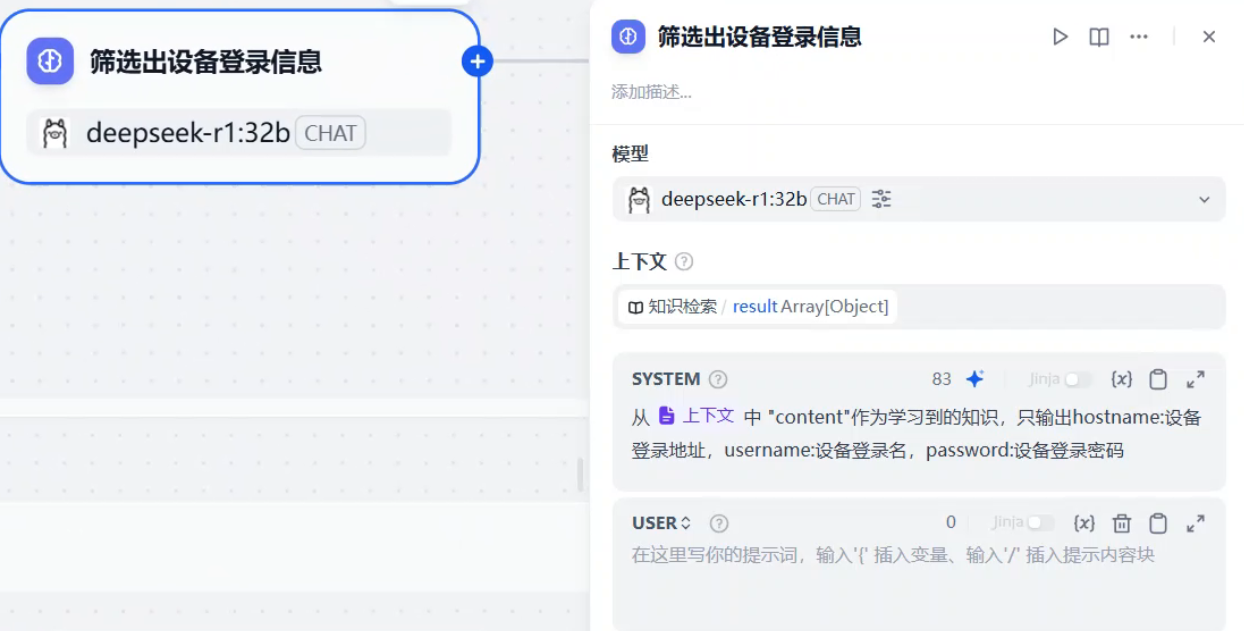
好了,接下来就可以用参数提取节点从LLM的输出中准确提取所要的信息了
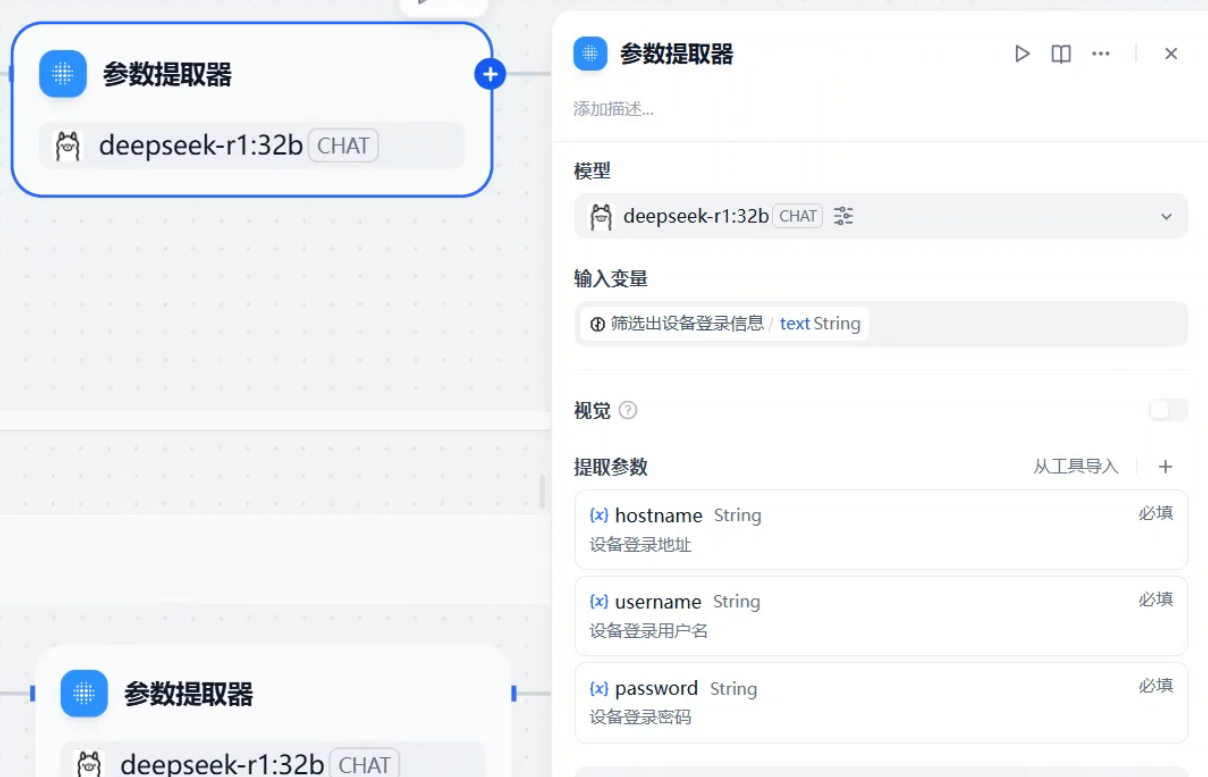
现在就可以连接我们的自定义工具了,工具所需变量都从参数提取节点获取。由于我的设备是华三的交换机,所以命令这部分我手动填写。当然工具可以扩展,command这部分参数也可以由大模型根据需要给你填写,扩展性强
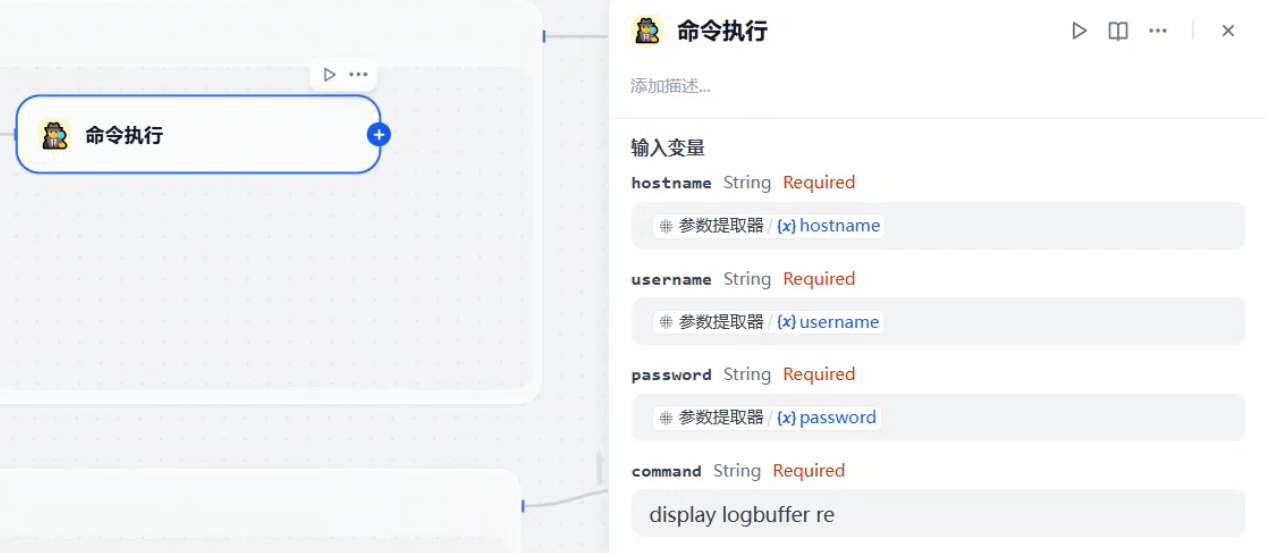
最后设置一个输出节点将迭代的结果输出
同理另一个迭代节点用于配置巡检的同理
演示
最后给大家看下效果,可以单独运行工作流,也可以将工作流发布为工具在chatflow里进行多轮对话。在此不在扩展,大家有兴趣的可以自行研究。由于此工作流主要做的是自动化将设备日志或者配置以jason格式输出,所以临时接了个LLM节点在后面用于效果展示,不在赘述。
此外工作流支持生成api调用,大家有兴趣也可以用于开发自己的工具,具体请参考工作流中的api文档。
启动工作流会得到这样一个页面,选择巡检的选项。上传需要巡检的设备清单(只需要包含设备名),选择巡检选项,然后点击运行。
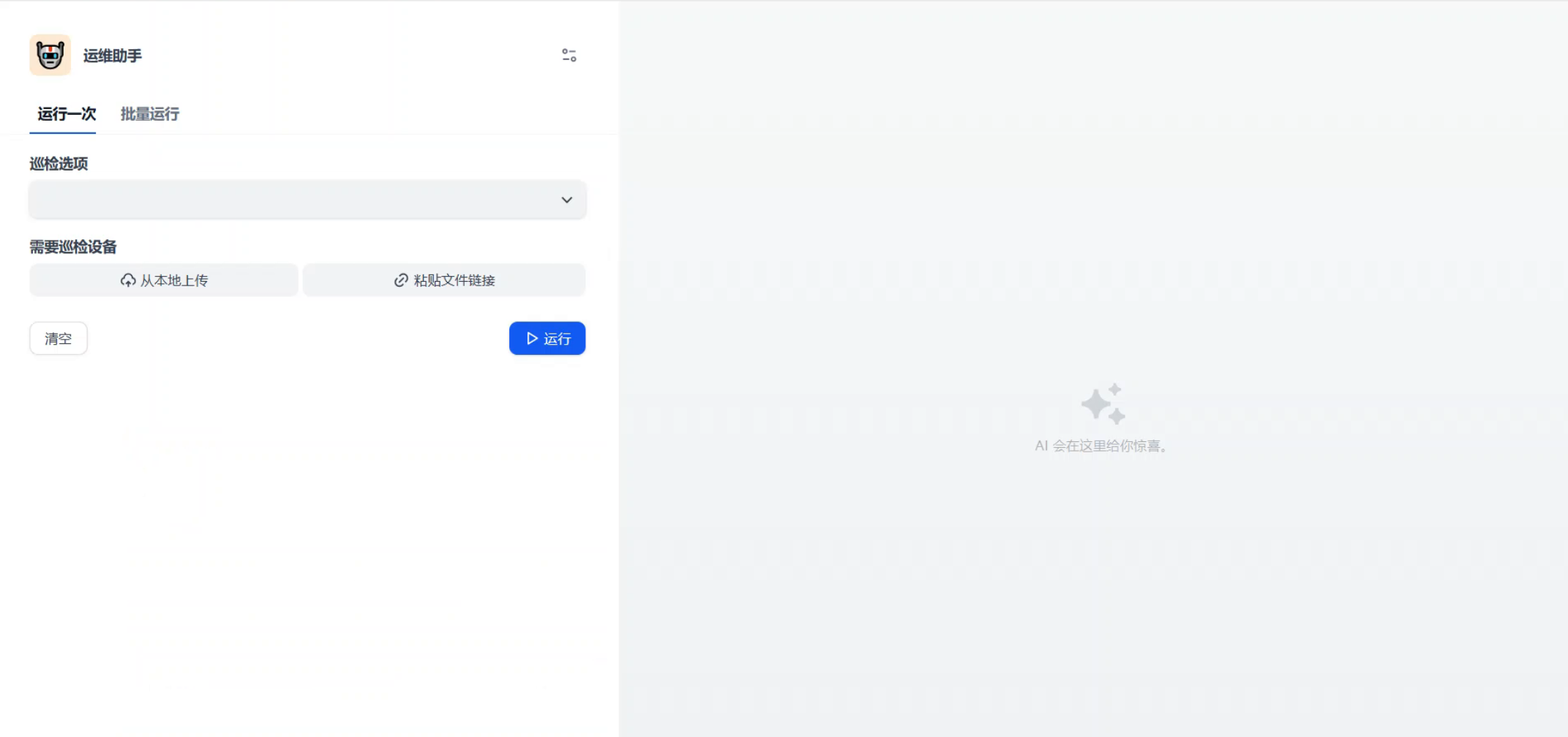
输出比较长,给大家展示一部分:


