

LobeChat配置向量模型实现文件上传和构建知识库
由于lobechat模式使用openai的向量模型,国内环境基本没法访问到,所以向量化会失败,我们需要用其他向量模型来实现。
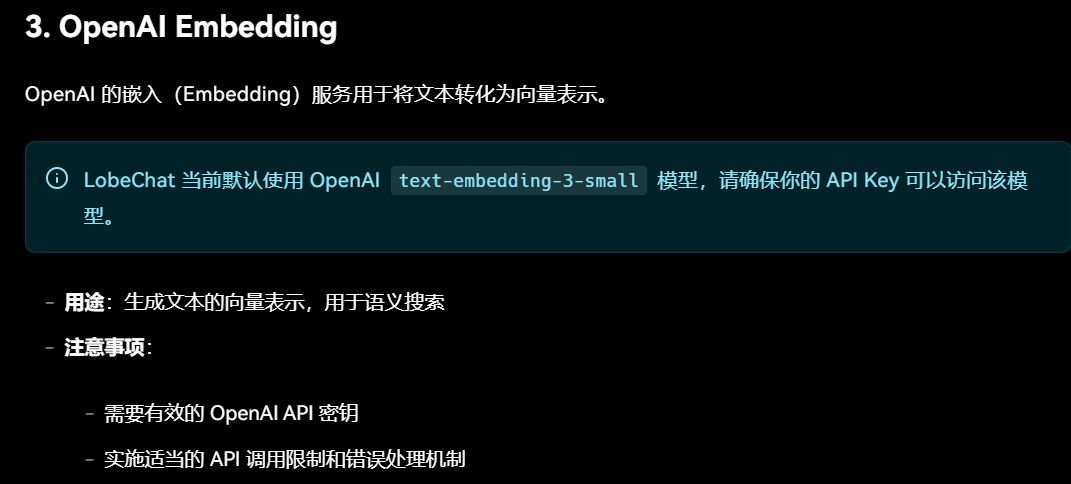
按照如下方法处理:
通过指定环境变量OPENAI_PROXY_URL=,通过代理请求到text-embedding-3-small模型
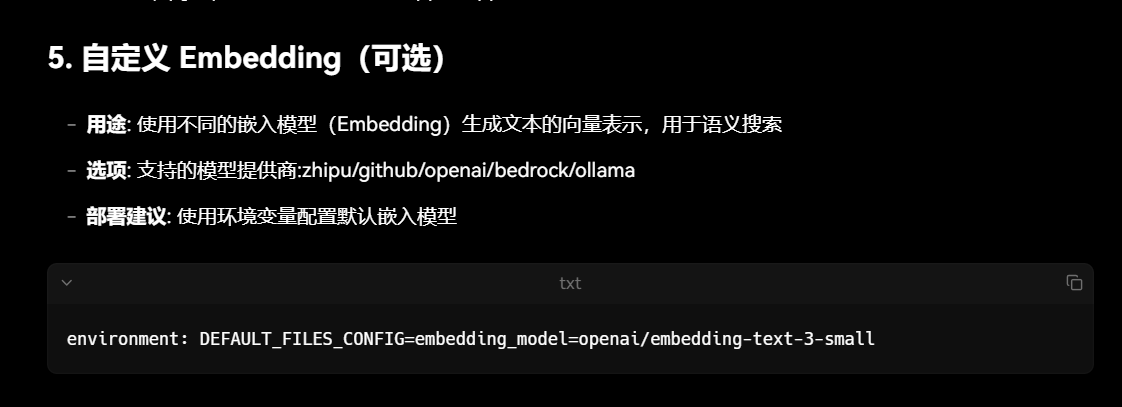
通过指定其他模型服务商的向量模型,目前支持的:zhipu/github/openai/bedrock/ollama,环境变量 DEFAULT_FILES_CONFIG=embedding_model=
 这里以智谱的embedding-3为例,embedding-2的调用会一直报错API请求参数错误,等后续更新吧。添加环境变量:DEFAULT_FILES_CONFIG=embedding_model=zhipu/embedding-3,ZHIPU_API_KEY=xxxx
这里以智谱的embedding-3为例,embedding-2的调用会一直报错API请求参数错误,等后续更新吧。添加环境变量:DEFAULT_FILES_CONFIG=embedding_model=zhipu/embedding-3,ZHIPU_API_KEY=xxxx
这里会有个问题,智谱文档里embedding-3:支持自定义向量维度,建议选择256、512、1024或2048维度。但lobechat在调用的时候默认是256的维度,所以需要改下数据库,不然向量化插入数据的时候就会报错:ERROR: expected 2048 dimensions, not 256。
#在PostgreSQL数据库执行将维度改为256
alter table embeddings alter column embeddings type vector(256);
本文是原创文章,完整转载请注明来自 牛马小航

评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果