

分享一个AI求职助理,解放双手,坐等Offer!
又到了毕业季,大家是否还在为海量的招聘信息而眼花缭乱,为每天重复的筛选、匹配工作而苦恼?作为一名“身经百战”的求职者,我深知其中的不易。但今天,我想给你分享一个能让你“解放双手,坐等Offer”的AI求职助理!
这是一个由AI驱动的自动化求职神器,它能每日自动抓取、分析和匹配全网的职位信息,并通过邮件为你推送一份专属的个性化求职报告。想象一下,每天早上,在你享用早餐时,一份已经为你精心筛选和分析过的岗位清单就已经躺在你的邮箱里了,是不是很酷?对你有用的话请给项目点个星。
✨ 它有多智能?核心功能一览
在深入教程之前,先来看看这个AI求职助理有哪些“超能力”:
📡 多源数据聚合:它能自动从各种渠道(如RSS订阅源、特定招聘网站)获取最新的职位信息。
🕷️ Firecrawl强力抓取:集成了强大的Firecrawl服务,能够轻松绕过反爬虫机制,精准抓取那些由JavaScript动态渲染的复杂网站(比如智联招聘)。
🧠 AI智能分析:这绝对是它的核心!它利用强大的大语言模型(例如Gemini)对所有职位进行深度分析和匹配。通过先进的“分块处理”机制,即使面对海量的职位信息也能稳定高效地完成任务,完全不用担心Token限制。
🎯 个性化匹配:你只需要在配置文件中填入你的学历和专业背景,AI就会像一个资深HR一样,为你筛选出高度相关的核心岗位和那些有巨大潜力的机会,并给出详尽的推荐理由。
📬 定时邮件推送:每天在你设定的时间,一份排版精美的HTML求职报告会自动发送到你的邮箱,让你再也不会错过任何好机会。
⚙️ 高度灵活配置:从AI模型、邮件服务,到爬虫目标和你的个人信息,所有的一切都可以通过一个简单的
.env文件进行配置,完全不需要改动任何代码。
🚀 小白也能轻松上手:保姆级部署教程
准备工作:在部署AI助理前的两个关键步骤
在正式“召唤”我们的AI求职助理之前,还需要一些准备工作。我们需要为它提供“原材料”——也就是招聘信息。下面的两个步骤将教你如何配置两个最重要的数据来源:微信公众号文章和主流招聘网站。
第一步:搭建你自己的RSS服务 (以 we-mp-rss 为例)
我们的AI助理可以通过RSS协议来读取信息,但很多信息源(比如微信公众号)本身不支持RSS。因此,我们需要一个“转换器”,将公众号文章转换成标准的RSS订阅源。we-mp-rss 就是一个非常优秀的开源工具,对你有用的话可以点个星支持下作者。
1. 为什么需要它? 简单来说,we-mp-rss 可以让你订阅的那些发布招聘信息的公众号,变成AI助理能够理解和抓取的数据源。
2. 部署步骤
使用Docker拉取we-mp-rss镜像
docker pull docker.1ms.run/rachelos/we-mp-rss:latest运行WeWeRSS容器
mkdir we-mp-rss cd we-mp-rss docker run -d --name we-mp-rss -p 8001:8001 -v ./data:/app/data docker.1ms.run/rachelos/we-mp-rss:latest如何使用WeWeRSS
访问服务,通过http://<localhost或者服务器ip>:8001/打开登录页面。
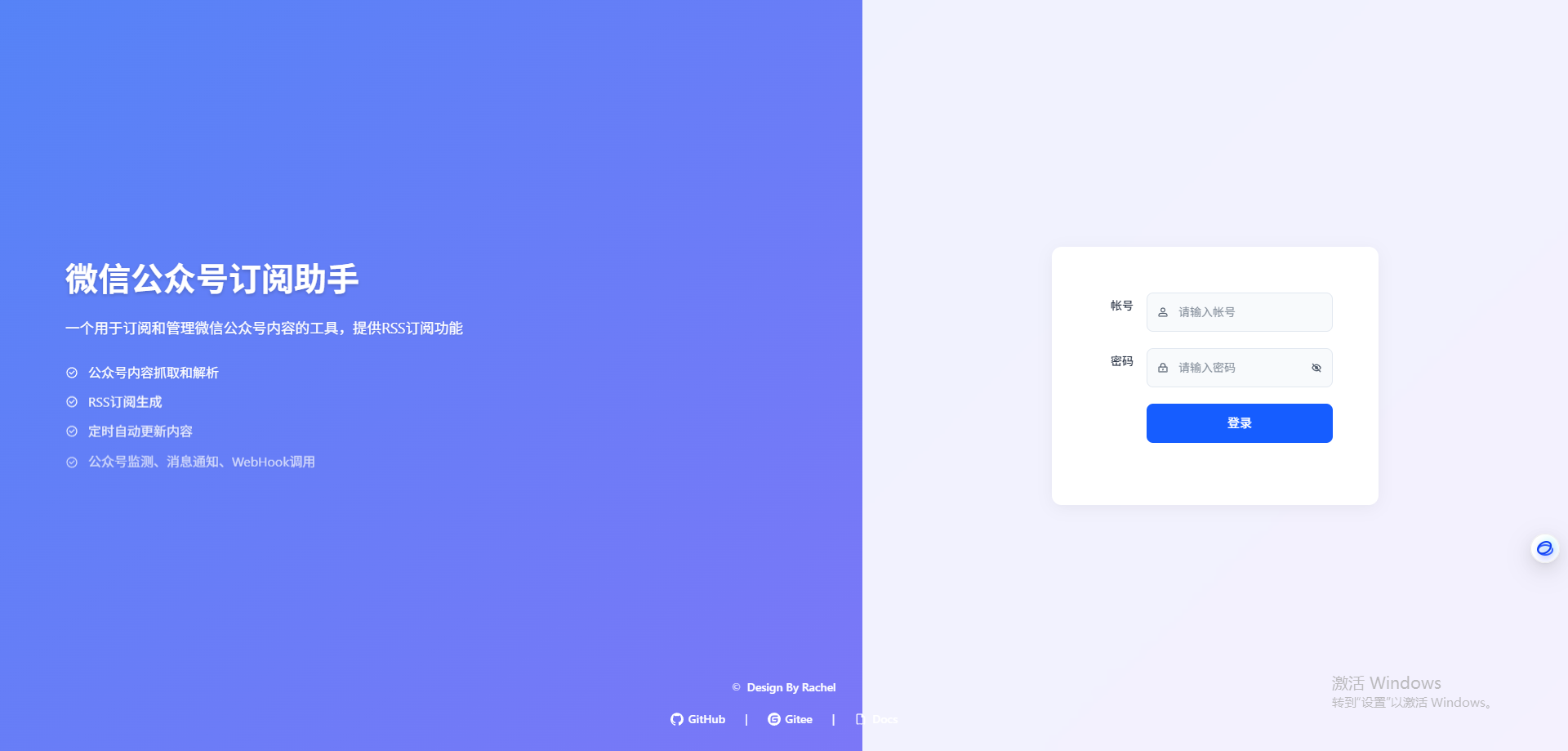 输入账号admin,密码admin@123,后续可以自行更改,点击登录。
输入账号admin,密码admin@123,后续可以自行更改,点击登录。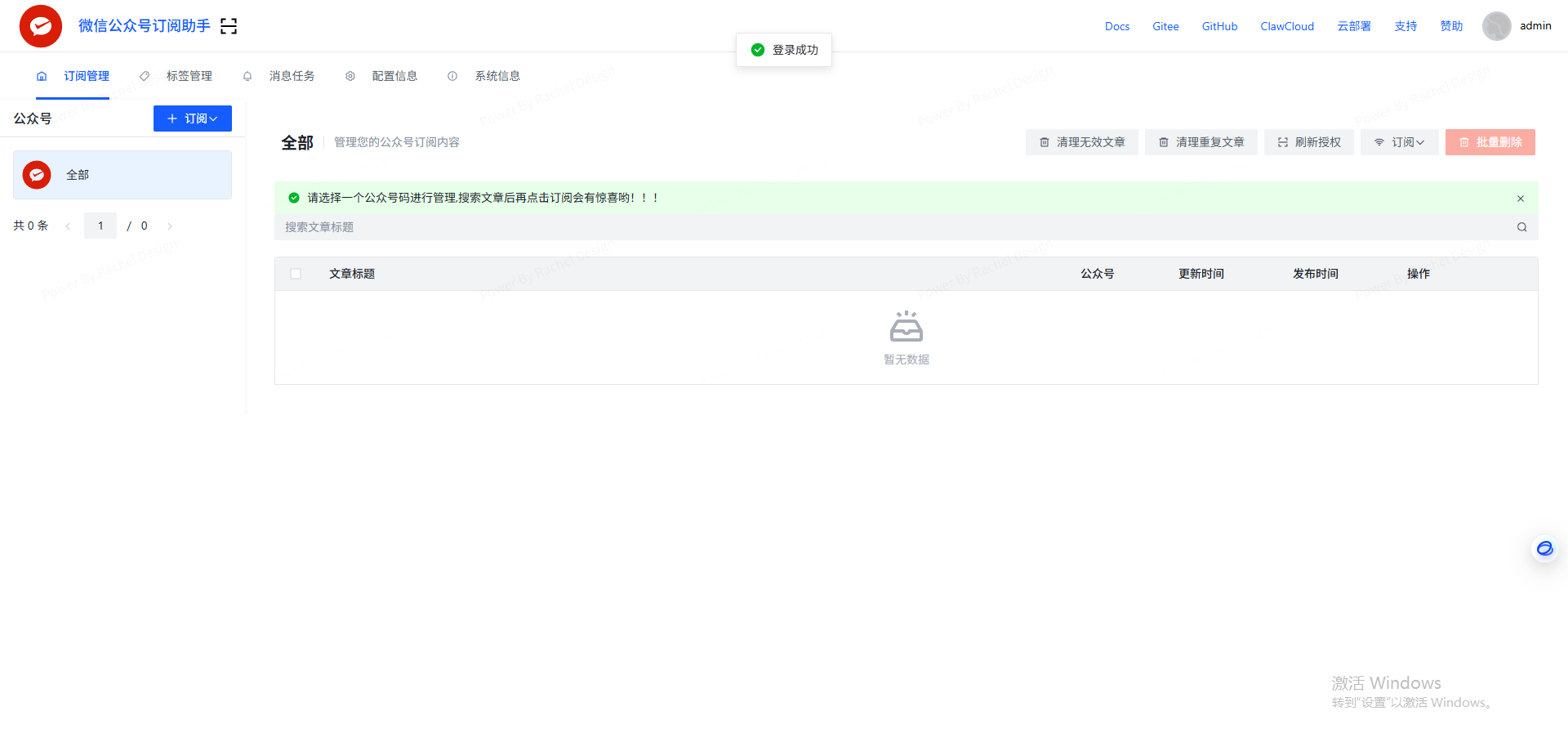
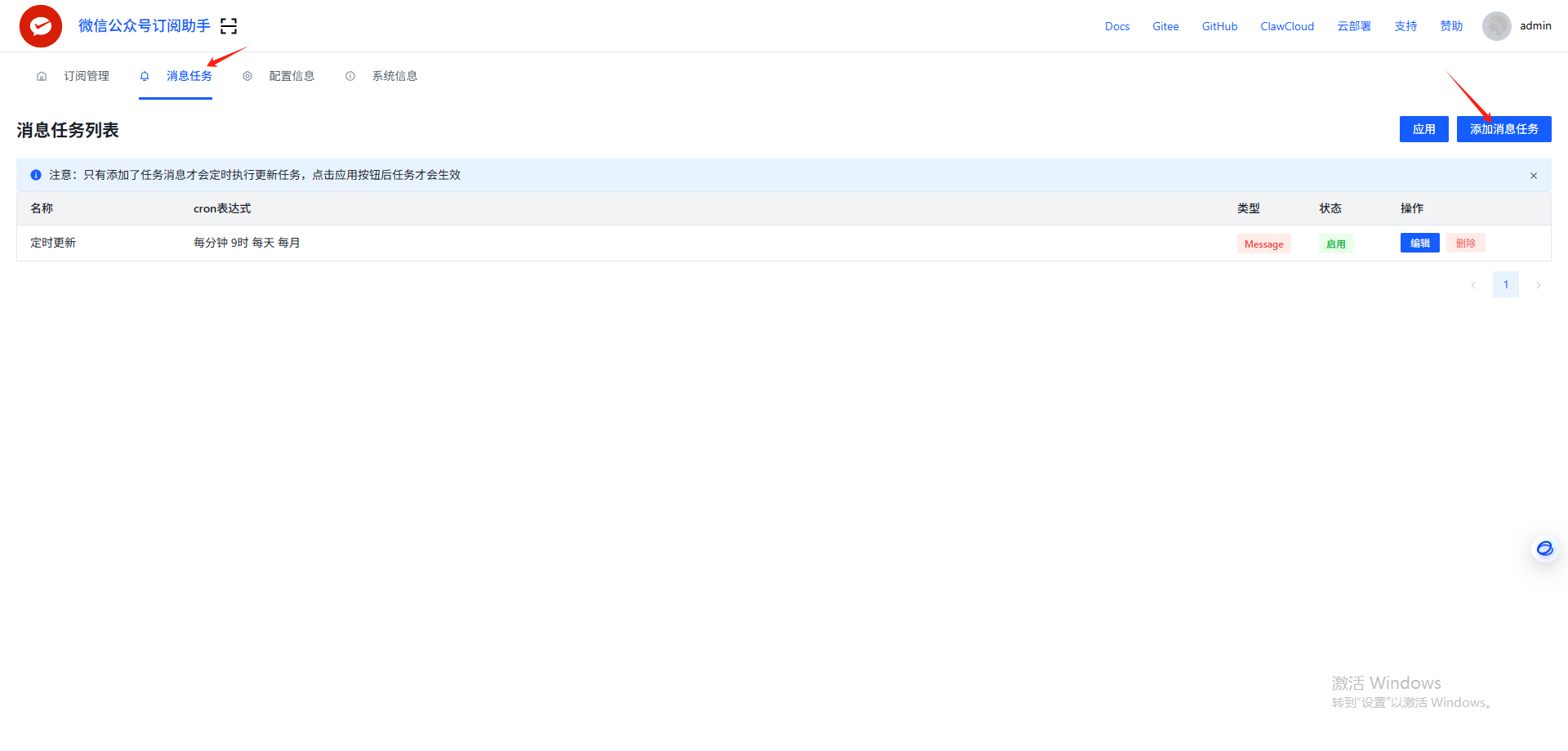
关注公众号并生成RSS链接,点击左上角扫码授权,需要自行注册个人公众号。扫描成功后,点击订阅,搜索需要订阅的公众号。
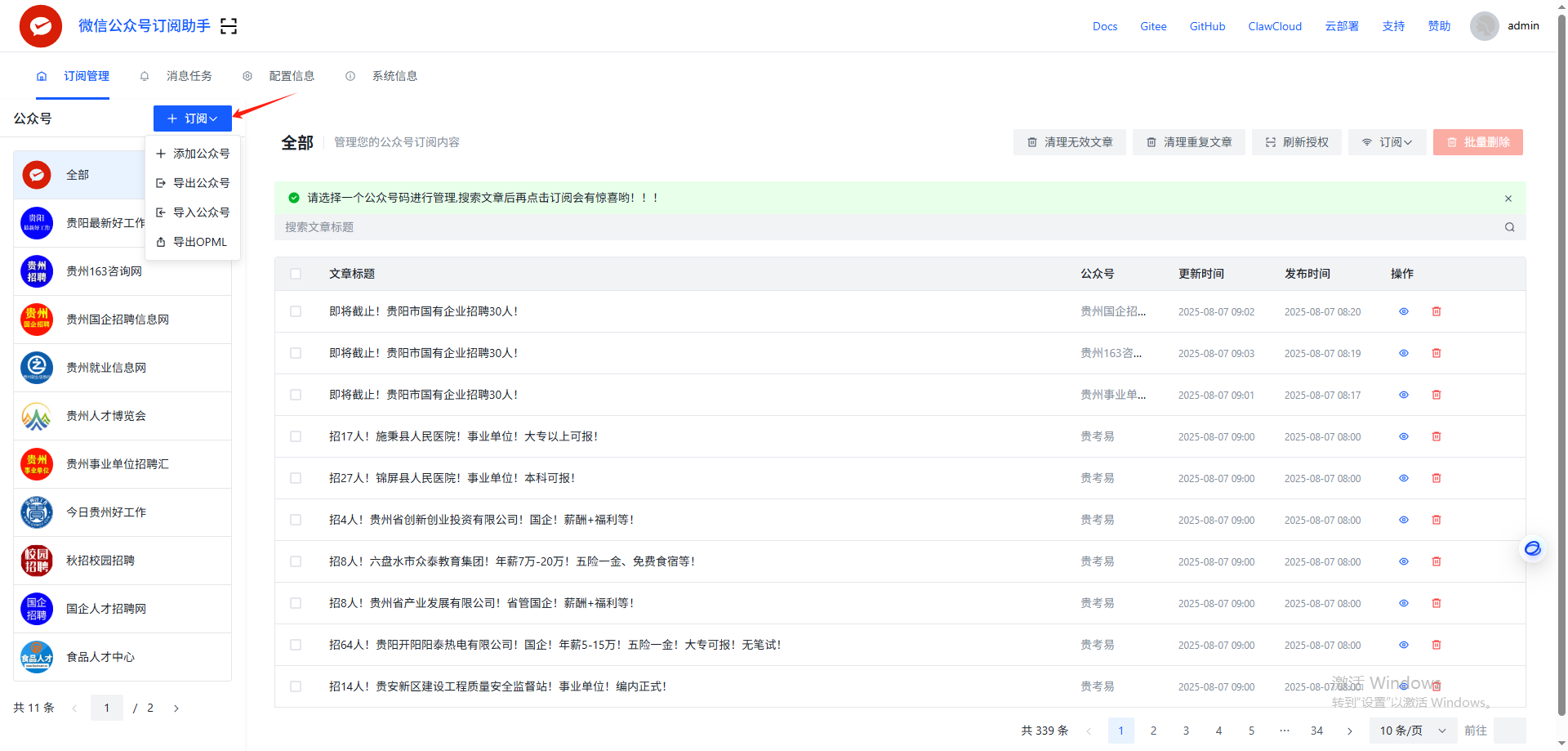
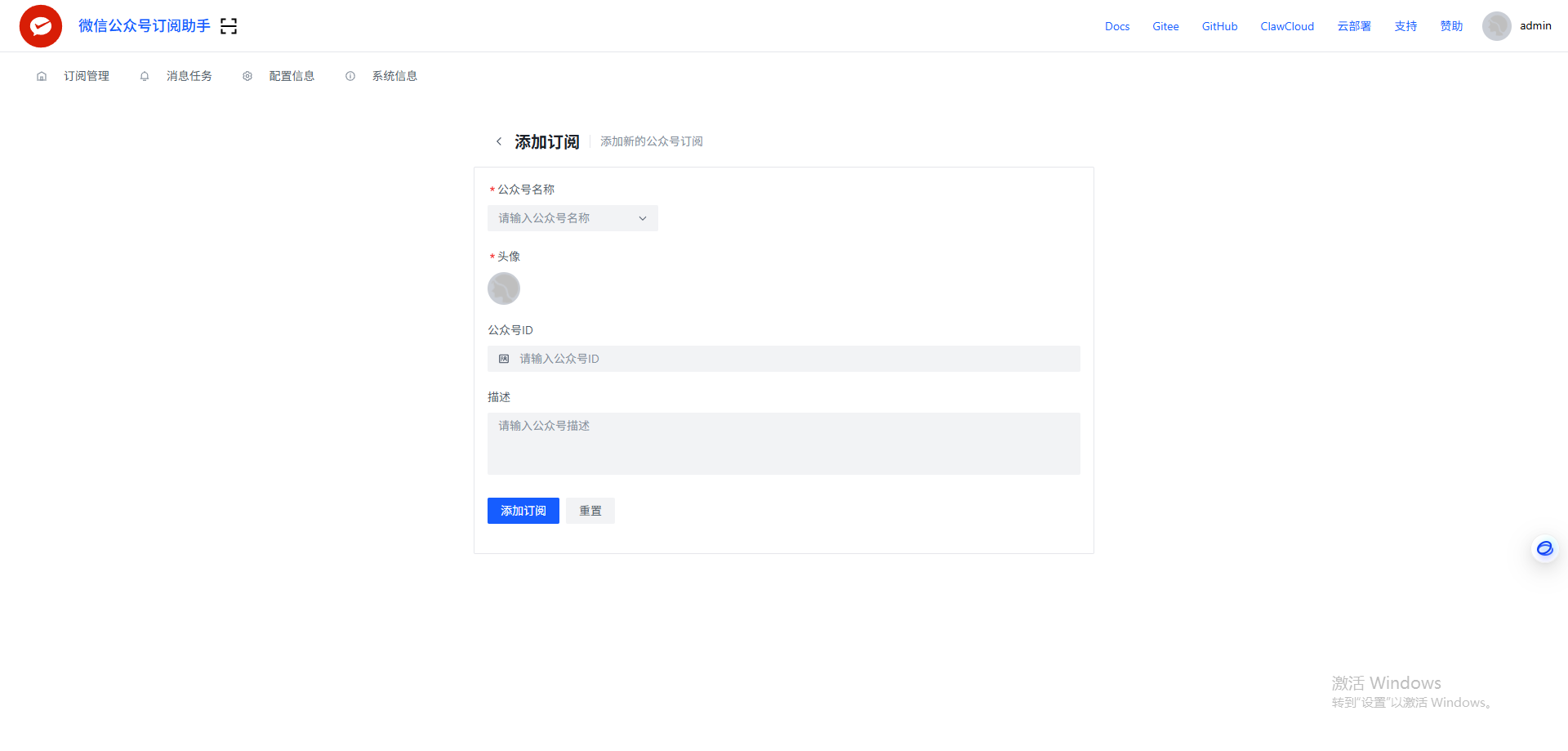
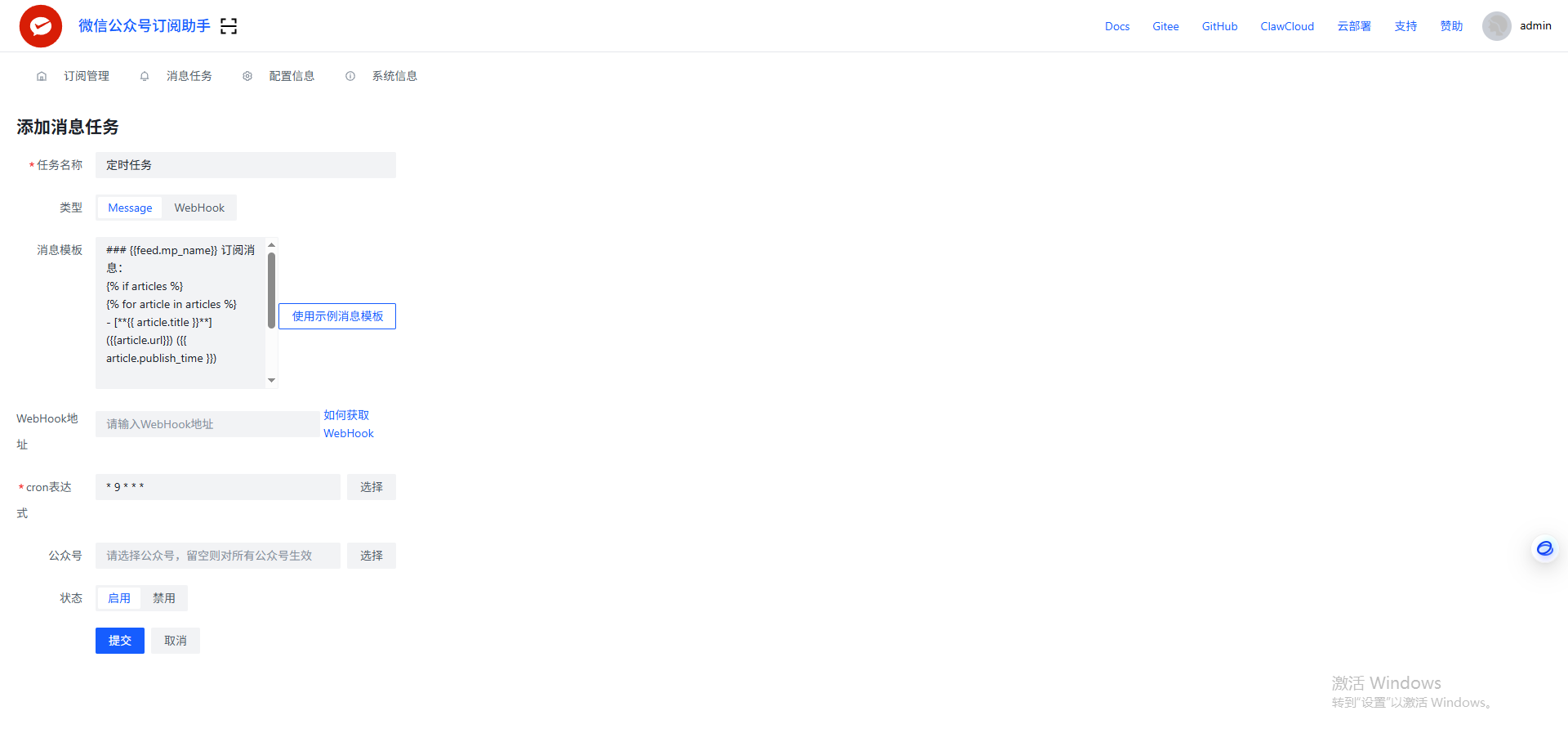
为了定时更新公众号的文章,我们配置一个定时任务,cron表达式有中文解释,按自己需要配置。配置完毕后,点击应用让任务生效。
在所需要公众号订阅完后,导出包含所有订阅源的
OPML文件(我们的AI助理会直接使用这个文件)。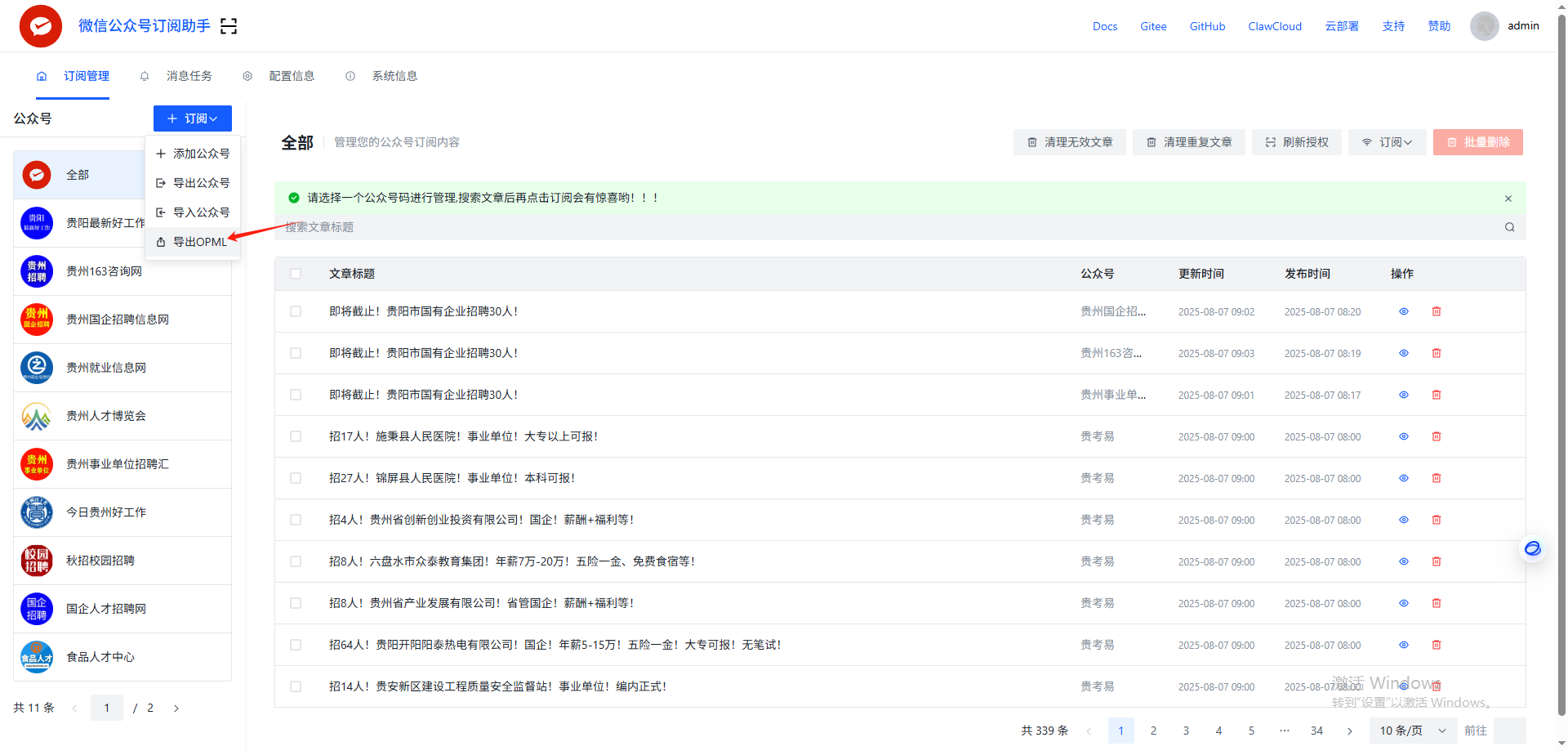
第二步:获取并配置招聘网站的URL
除了公众号,更直接的招聘信息来源是各大招聘网站,例如智联招聘。我们需要手动获取一个包含我们搜索条件的网址,并把它配置给AI助理。
1. 为什么要这么做? 这一步是为了告诉AI助理:“我只对这个城市、这个关键词的岗位感兴趣,请你每天帮我关注这些就行了。”
2. 操作指南
打开招聘网站:例如,在浏览器中打开
zhaopin.com。输入你的求职意向:
在搜索框中输入你心仪的 岗位关键词(如:
Python、Java、产品经理)。选择你想要工作的 城市(如:
北京、上海)。
执行搜索并复制URL:
点击“搜索”按钮。
在搜索结果页面,从浏览器地址栏 完整复制整个URL。它可能看起来像这样:
https://www.zhaopin.com/sou/jl489/kwpython/p1/
修改URL用于配置:
这是最关键的一步!我们需要把URL中的 页码 替换为占位符
{page}。这样做是为了让AI助理能够自动翻页抓取。根据上面的例子,修改后的URL应该是:
https://www.zhaopin.com/sou/jl489/kwpython/p{page}/最后,将这个修改好的URL填入我们项目
.env文件的ZHAOPIN_SEARCH_URL配置项中。
第三步:部署并启动AI求职助理
1. 下载项目代码
首先,你需要把 job-agent 的所有代码文件下载到你的电脑上。打开你的终端(或命令行工具),执行以下命令:
# 从GitHub克隆项目,克隆有困难的用户,请自行搜索github代理
git clone https://github.com/luohang7/job-agent.git
# 进入项目目录
cd job-agent2. 配置你的专属 .env 文件 (最关键的一步!)
AI助理需要知道你的个人偏好、邮箱配置以及API密钥才能为你工作。这些信息都存储在一个名为 .env 的配置文件中。
在
job-agent目录下,你会看到一个叫.env.example的模板文件。请先把它复制一份,并重命名为
.env。然后,用你喜欢的文本编辑器(如VS Code、记事本等)打开这个新的
.env文件,把里面的信息替换成你自己的。
# .env
# --- AI 模型与服务 ---
# Firecrawl API,用于抓取JS渲染的网站 (必需),在此获取https://www.firecrawl.dev/app/api-keys
FIRECRAWL_API_KEY=fca_...
# 大语言模型 API (必需)
OPENAI_API_KEY=你的OpenAI或Gemini的API_Key
OPENAI_BASE_URL=https://api.openai.com/v1 # 如果使用代理,请填写代理地址
GEMINI_MODEL_NAME=gemini-1.5-flash-latest # 使用的模型名
# --- SMTP 邮件服务配置 (必需) ---
SMTP_SERVER=smtp.qq.com # 你的邮箱SMTP服务器地址
SMTP_PORT=465 # 端口号 (QQ邮箱SSL端口是465)
SMTP_USERNAME=你的发信邮箱地址@qq.com
SMTP_PASSWORD=你的邮箱授权码(不是登录密码!)
RECIPIENT_EMAIL=接收报告的邮箱地址
# --- 用户个人信息 (必需) ---
USER_EDUCATION=本科
USER_MAJOR=计算机科学与技术
# --- 爬虫目标配置 (必需) ---
# 把我们上一步获取并修改好的招聘网址粘贴到这里
ZHAOPIN_SEARCH_URL=https://www.zhaopin.com/sou/jl489/kwpython/p{page}
ZHAOPIN_MAX_PAGES=3 # 希望抓取的总页数
# RSS订阅源文件路径,保持默认即可
OPML_FILE_PATH=data/rss_feed.opml3. 准备 data 目录
还记得我们在第一步里从 we-mp-rss 服务导出的 OPML 文件吗?现在该把它放进正确的位置了。
在
job-agent目录下,手动创建一个名为data的文件夹。将你导出的
rss_feed.opml文件(或其他名字的OPML文件)放入这个data文件夹内。
4. 一键启动!
所有准备工作都已完成!现在,请确保你的 Docker 正在运行,然后在 job-agent 的项目根目录下,执行这行神奇的命令:
docker run -d --env-file ./.env -v ./data:/app/data --name job-agent luohang2333/job-agent:latest注意: -v ./data:/app/data 会将当前目录下的 data 文件夹挂载到容器的 /app/data 目录。请确保在执行命令的路径下有正确的 .env 和 data 文件。
当命令执行完毕,你的AI求职助理就已经在后台开始辛勤工作了!它会根据你在 .env 文件中设置的 EMAIL_SEND_TIME,每天定时运行并给你发送邮件报告。
5. 如何查看它的工作状态?
如果你想看看AI助理的实时工作日志,可以执行以下命令:
docker logs -f job-agent6. 如何停止服务?
当你暂时不需要它工作时,可以执行以下命令来停止服务:
docker stop job-agent
docker rm job-agent至此,整个部署流程就全部完成了!你已经成功拥有了一个属于自己的、7x24小时不间断的AI求职伙伴。现在,你只需要每天早上悠闲地端起咖啡,查收它为你精心准备的求职报告就可以了。祝你早日拿到心仪的 Offer!
进阶部署:在云端平台 Zeabur 上实现7x24小时运行
为什么选择云端部署?
为了让AI助理不间断地监控招聘信息,我们需要一个能24小时运行的环境。对于没有个人服务器的同学,使用Zeabur等云平台是最佳选择,它提供免费的额度,并且部署非常简单。
部署步骤
从zeabur一键部署,在job-agent服务中修改对应的环境变量
https://zeabur.com/zh-CN/templates/6SNWGJ 
配置rss的域名
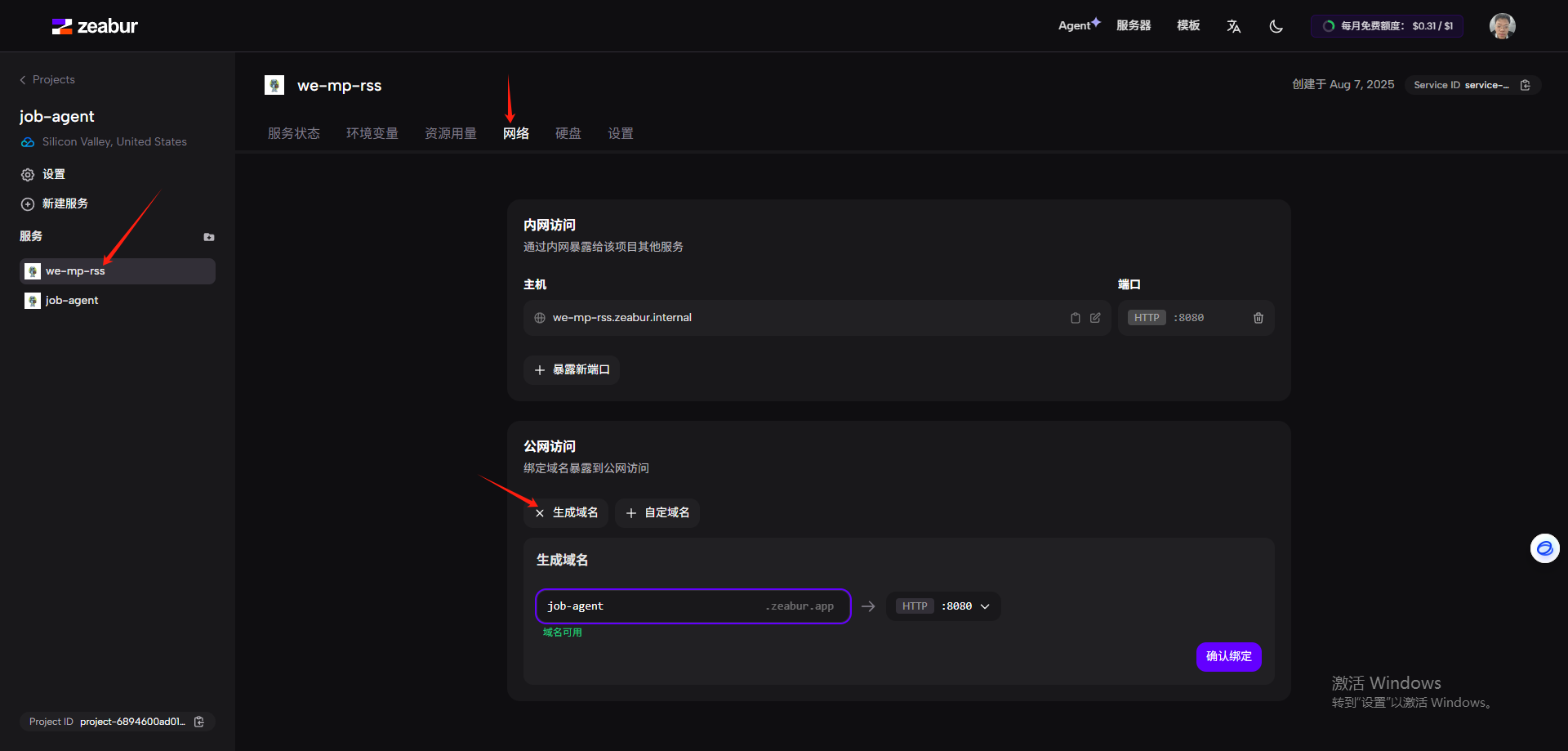
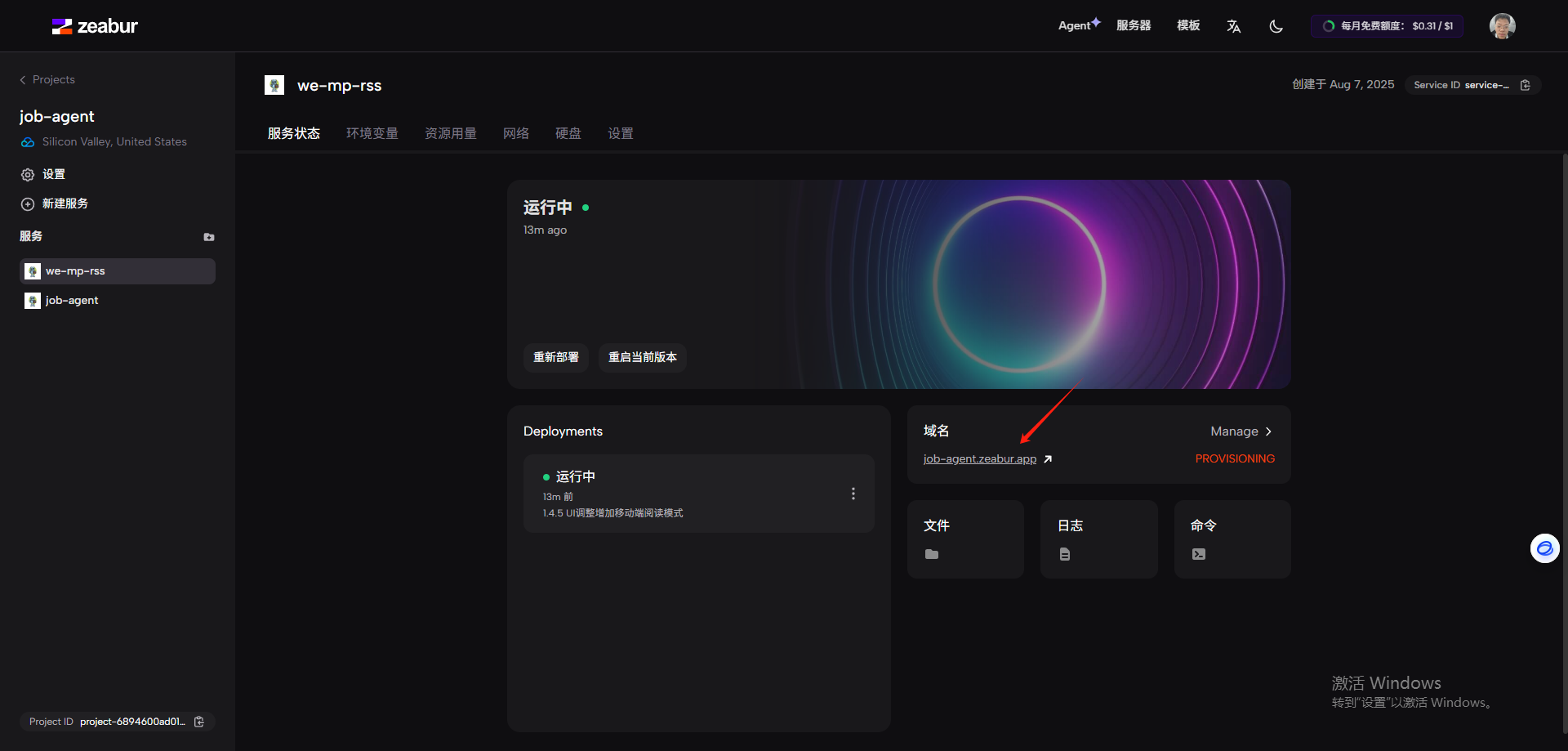
打开登录,用户名admin,密码在环境变量的PASSWORD里,接下来的操作参考docker部署里如何订阅公众号。
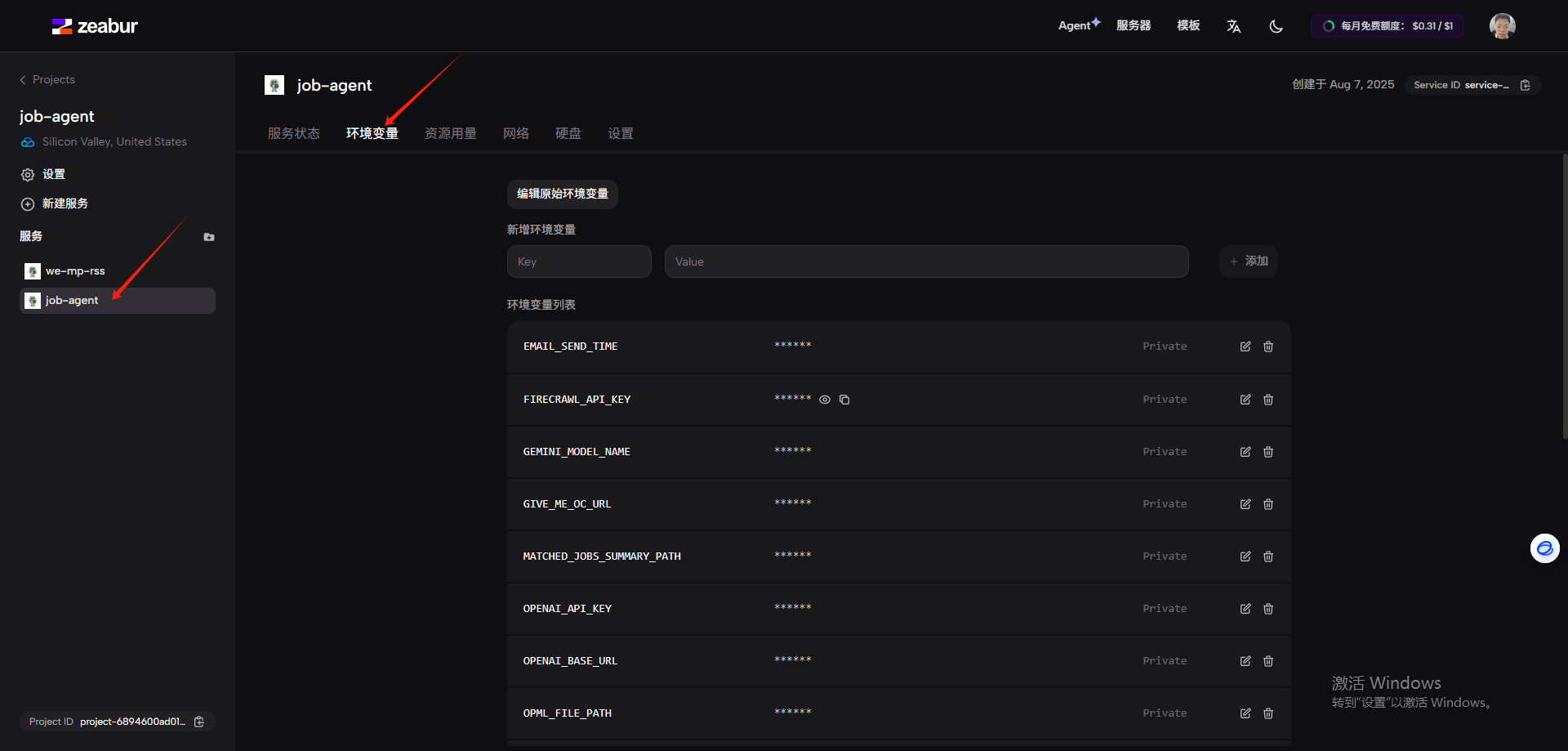
配置job-agent的环境变量,参考docker部署,修改记得重启服务。
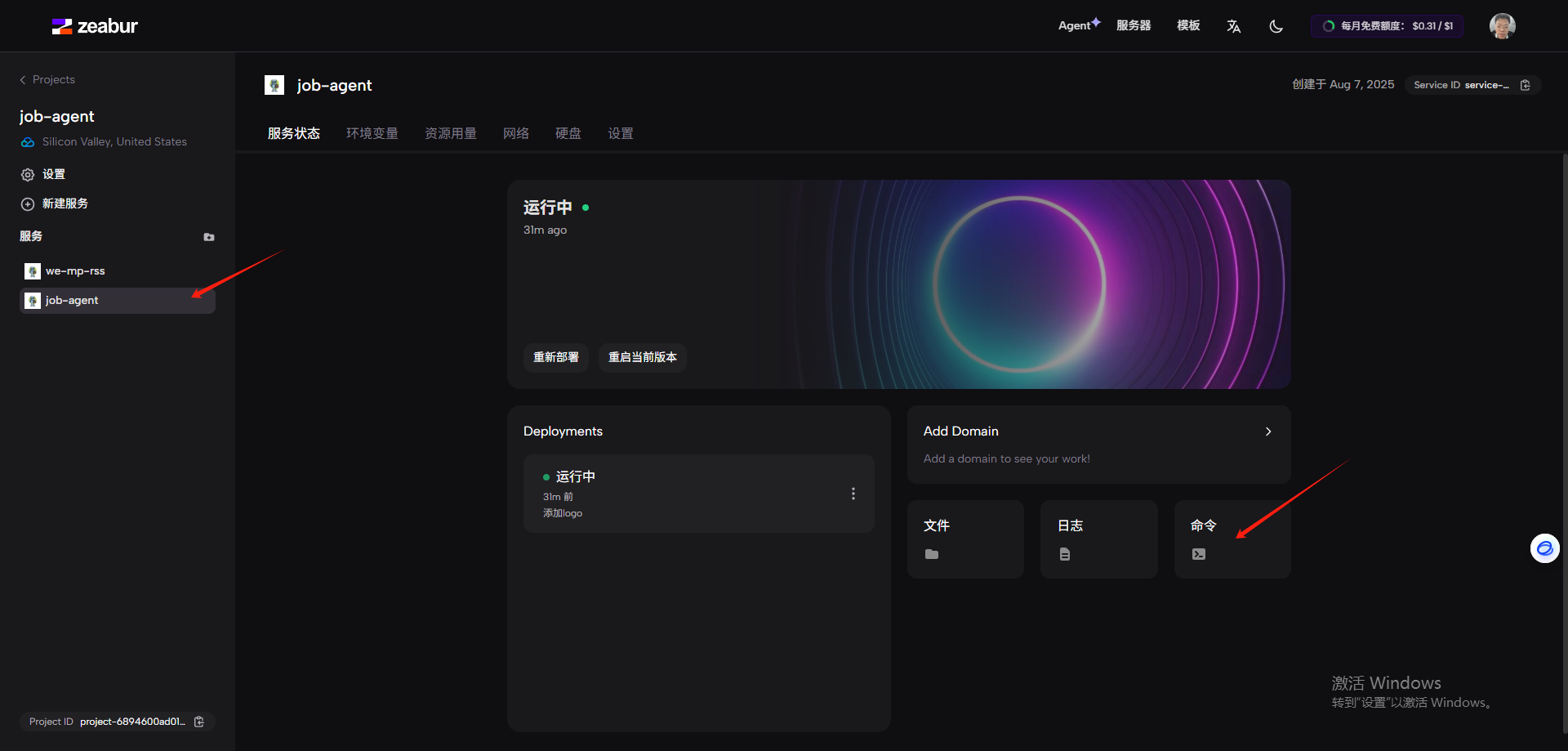
将从rss中获取的opml文件在job-agent中创建文件,将opml的内容复制进入,然后点击命令将文件移动到目标目录
mkdir -p /app/data cd data touch rss_feed.opml # 参考以下格式将文件内容写入 cat <<EOF > /app/data/rss_feed.opml <?xml version="1.0" encoding="UTF-8"?> <opml version="2.0"> <head> <title>我的RSS订阅</title> </head> <body> <outline text="招聘信息源" title="招聘信息源"> <outline type="rss" text="一个公众号的RSS" xmlUrl="这里替换成你的RSS链接"/> </outline> </body> </opml> EOF
